This post is a continuation of a series which at this point should just be called "productionalizing side projects that will never actually see the light of day".
As mentioned in a previous post, this site - along with the rest of my internet presence - is hosted on a bare metal Kubernetes cluster which also serves as my homelab.
I am currently working on a side project which allows users to create authenticating middleware for their own services, and as part of this design, my service needs to communicate with their service(s).
This means allowing the client to provide an endpoint which will then be called from my service through an HTTP
HEAD request to retrieve certain data.
For the uninitiated, this would be fine. Ensure you are preventing SQL injection on your API / DB, lock down your ingress firewalls to only 443 (who needs 80 anymore, 301 that at the edge!), and call it a day, right? WRONG.
Before we dive into the technical details, let's first take a look at the "happy path" design.
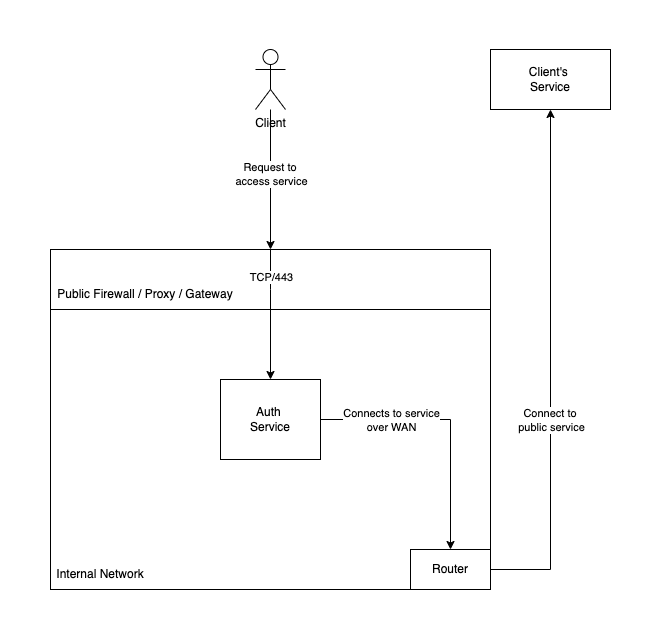
Take a minute to look at this diagram and try to spot the issue. In a perfect world, we are providing a service that when used properly, will issue a HEAD request to the user's defined upstream, retrieve the specified data, and return that to the user. Great.
But of course the world is not perfect, and little Bobby Tables is not an honest user.
The reality of most environments is that your application isn't the only thing that is running. Even if your app is running on a dedicated server, it most likely is part of a larger network which consists of other devices and services.
Let's add a new service to the diagram, this time inside our network. This is a BI tool only intended for internal use, and because the dev team that built it in COBOL left 15 years ago but the tool is business critical, it still runs on port 80 with no authentication.
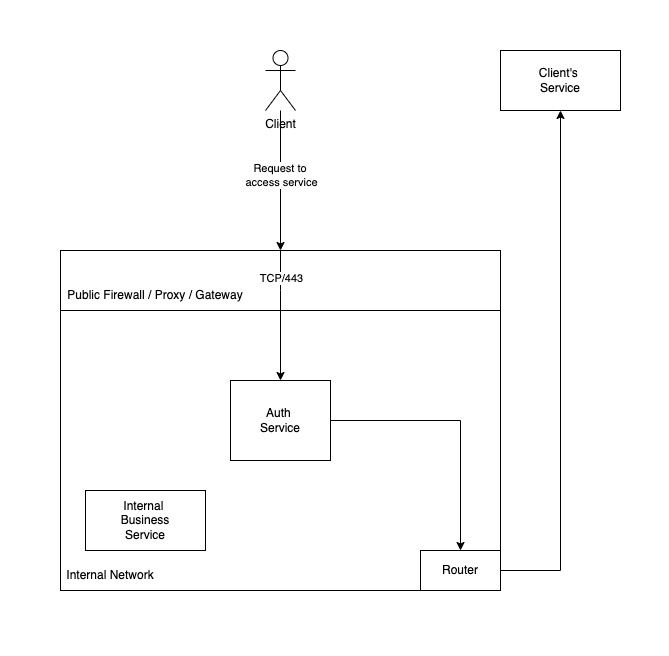
This is the same diagram as before, but now we have an internal service running on the same network as our main service. If our user is honest, they will continue to connect to their upstream service as before. But as already mentioned, users are never honest.
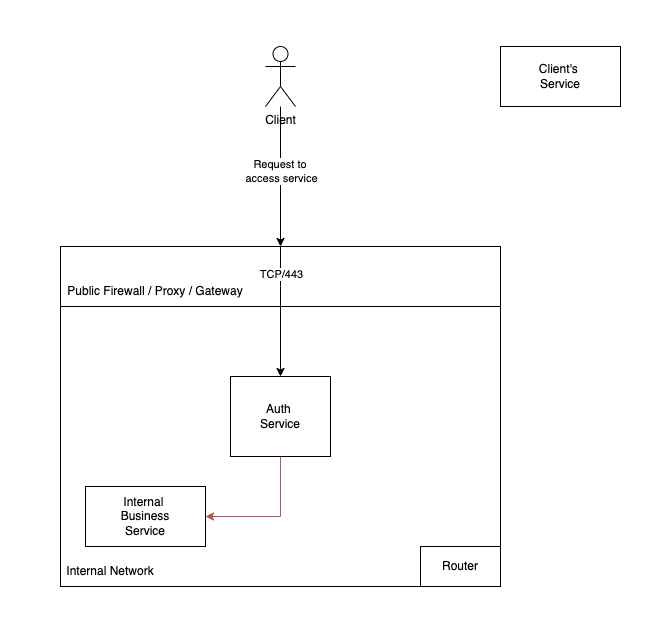
Let's say you use split-horizon DNS to optimize internal traffic and provide unified service names both internally and externally. So while outside your network
bi-tool.example.com points to an Authorizing Gateway / IP-NACL reverse proxy, inside your network bi-tool.example.com points directly to the internal server.
In this scenario, if an external client provides their upstream as
bi-tool.example.com, their request will be routed to the internal server.
Endpoints don't just need to be resolvable through split-horizon DNS for this exploit to work, the route just needs to exist. If the user provides a direct IP address, that will route without an issue either (since DNS is just an abstraction on top of IP stack).
With just a couple lines of bash, we could iterate the entire RFC1918 space and find all internal addresses, and if we didn't receive enough data there, we can then start crafting more endpoint-specific exploits.
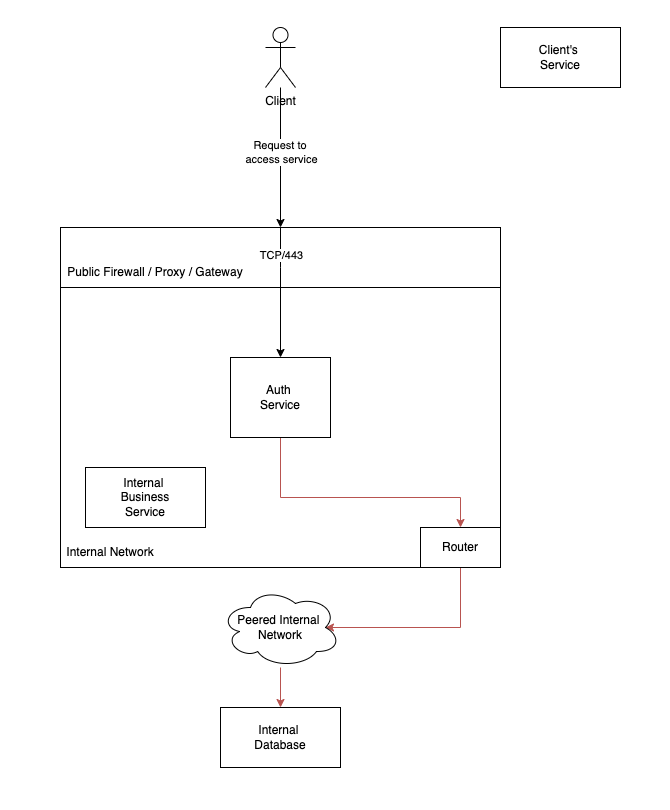
This is why reverse proxy configurations are so critical, since a single misconfiguration or misunderstanding of the overall network topology the proxy operates within can create an inadvertent hole in your security perimieter.
In a convetional network, you may just create an entirely disconnected subnet and run the service over there. But what if the service does need to communicate with some internal resources? In that case, may use route tables or Policy Based Routing (PBR) to restrict internal traffic flows. This becomes more difficult when operating an at-scale brownfield network which supports both "traditional" as well as "next gen" systems.
In K8s, we have very similar concepts of PBR through the K8s
NetworkPolicy resource. Istio extends this concept through the addition of AuthenticationPolicy and RequestAuthentication resources which enable granular ServiceAccount, JWT, and federated-IdP authentication of service-to-service communication. However as Istio auth policies are applied at the traffic desination, this model does not work for brownfield clusters in which services may have been initially launched under the implicit allow RBAC model, and still need integrations work to move towards an implicit deny model.
In this case, the K8s native
NetworkPolicy is a great solution. This allows us to create an implicit DENY ALL rule for all Egress traffic, and then create granular ALLOW rules for specific services.
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: example-allow-ingress
namespace: default
spec:
podSelector:
matchLabels:
app: restricted-upstream
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: example-downstream
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: example-default-deny
namespace: default
spec:
podSelector:
matchLabels:
app: restricted-upstream
policyTypes:
- Egress
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: example-egress-core
namespace: default
spec:
podSelector:
matchLabels:
app: restricted-upstream
egress:
# kube-dns required for DNS resolution
# we use the cluster-internal DNS rather than setting the pod
# resolver to public so that we can support internal upstreams
# however for security, internal upstreams should get their own
# granular net policies
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
- to:
# istiod is required for istio-envoy internal communications
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: istio-system
podSelector:
matchLabels:
app: istiod
ports:
- port: 15012
protocol: TCP
- to:
# example of an allowed internal service
- podSelector:
matchLabels:
app: allowed-internal
ports:
- port: 80
- to:
# allow egress to 0.0.0.0/0, excluding RFC1918. Any traffic destined
# for internal resources must match a more granular NetworkPolicy or be denied
- ipBlock:
cidr: 0.0.0.0/0
except:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
Now with these policies in place, the service will only be able to connect to pre-approved internal services, and then for all other IPs not in RFC1918 space, it will be allowed.
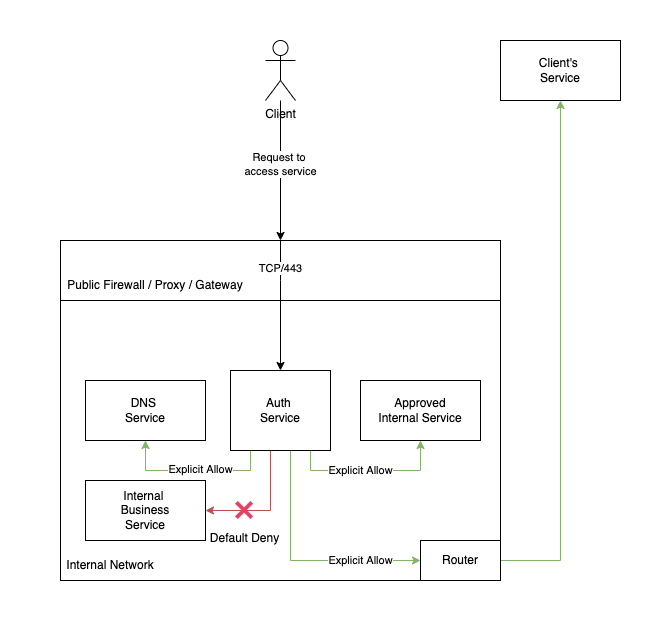
If you control your origins, great, you're done! However this of course does nothing to protect us if the external upstream service replies with malicious content (those of you yelling at the screen throughout the post that this was forgotten, it wasn't!), but it does provide a way to restrict access to internal services in a hybrid topology.
Protecting against malicious upstream / supply chain attacks will be the subject of a future post - the onion approach.
last updated 2025-05-11